论文地址 Deep Residual Learning for Image Recognition
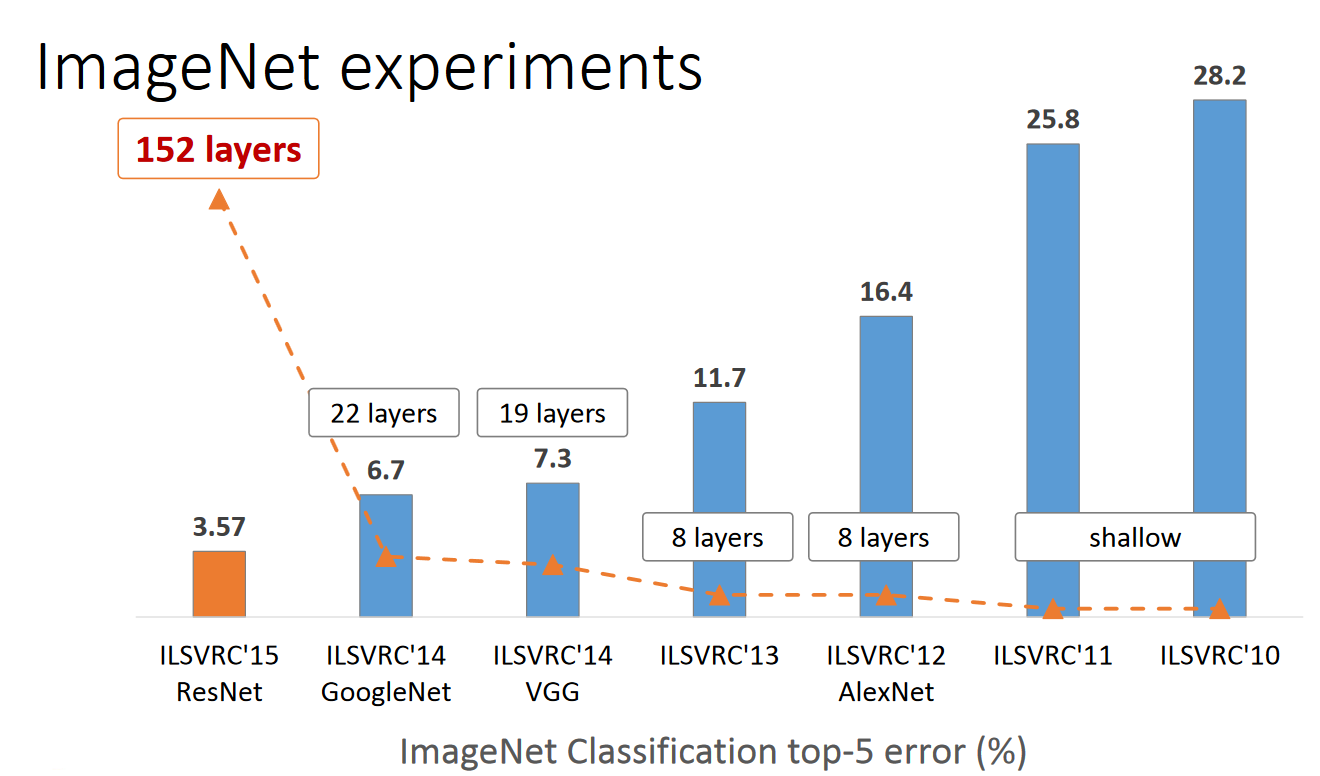
- ResNet —MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。就让我们来观摩大神的这篇上乘之作。
ResNet要解决的问题
首先一个问题是 vanishing/exploding gradients,即梯度的消失或发散。这就导致训练难以收敛。但是随着 normalized initialization and intermediate normalization layers的提出,解决了这个问题。
当收敛问题解决后,又一个问题暴露出来:随着网络深度的增加,系统精度得到饱和之后,迅速的下滑。让人意外的是这个性能下降不是过拟合导致的。对一个合适深度的模型加入额外的层数导致训练误差变大。如下图所示: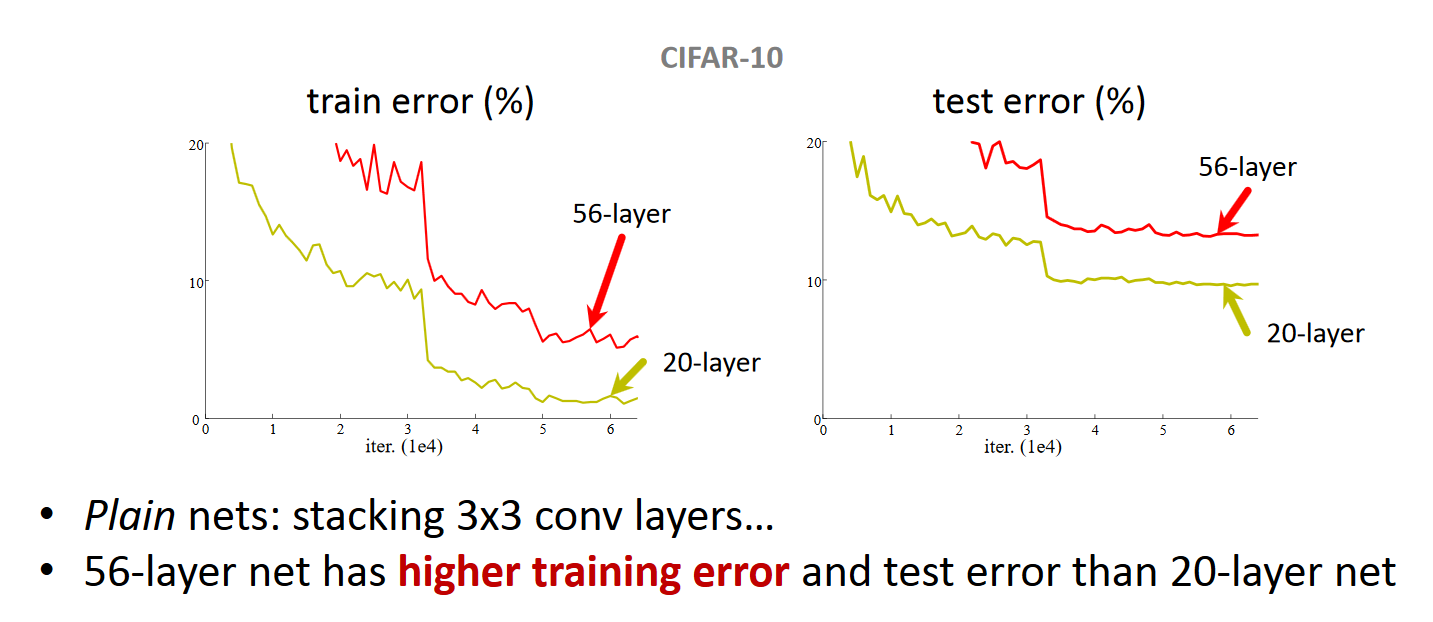
现在浅层的网络(shallower network)无法明显提升网络的识别效果了,所以现在要解决的问题就是怎样在加深网络的情况下又解决训练误差变大的问题。如果我们加入额外的 层只是一个 identity mapping,那么随着深度的增加,训练误差并没有随之增加。所以我们认为可能存在另一种构建方法,随着深度的增加,训练误差不会增加,只是我们没有找到该方法而已。
ResNet的解决方案
ResNet引入了残差网络结构(residual network),通过残差网络,可以把网络层弄的很深,据说现在达到了1000多层,最终的网络分类的效果也是非常好,残差网络的基本结构如下图所示 :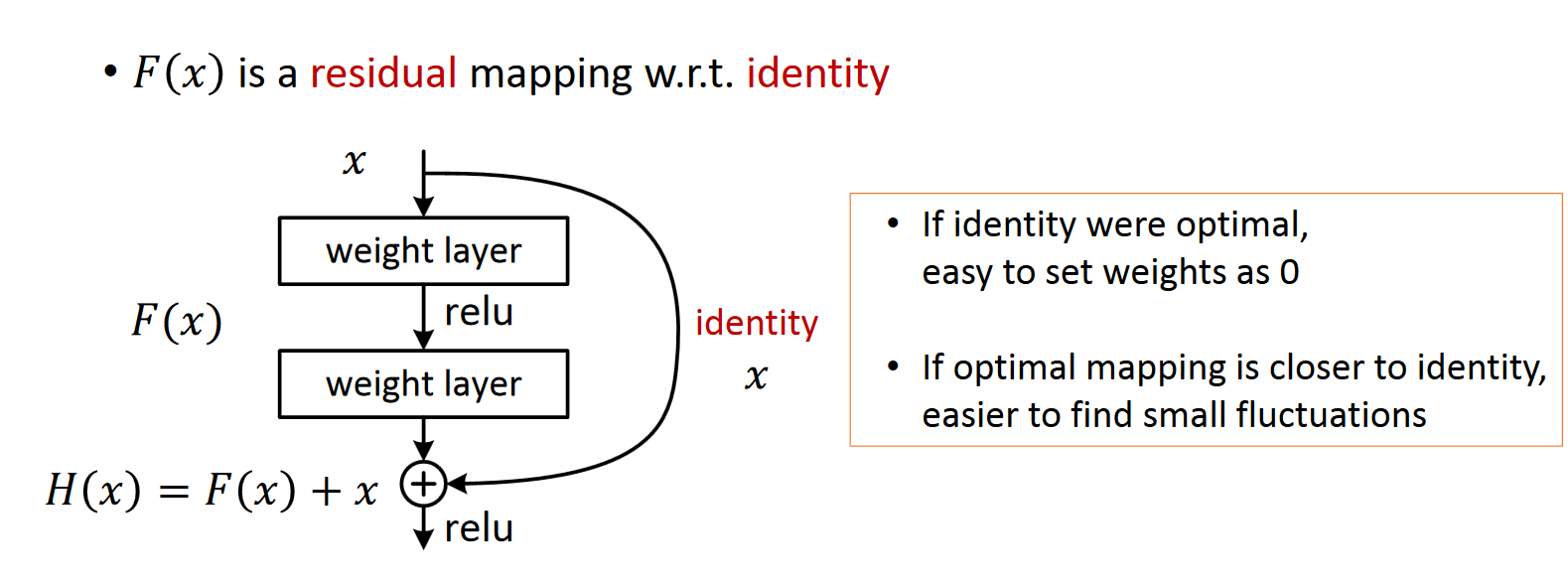
即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这里我们首先求取残差映射 F(x):= H(x)-x,那么原先的映射就是 F(x)+x。尽管这两个映射应该都可以近似理论真值映射 the desired functions (as hypothesized),但是它俩的学习难度是不一样的。
这种改写启发于 图1中性能退化问题违反直觉的现象。正如前言所说,如果增加的层数可以构建为一个 identity mappings,那么增加层数后的网络训练误差应该不会增加,与没增加之前相比较。性能退化问题暗示多个非线性网络层用于近似identity mappings 可能有困难。使用残差学习改写问题之后,如果identity mappings 是最优的,那么优化问题变得很简单,直接将多层非线性网络参数趋0。
实际中,identity mappings 不太可能是最优的,但是上述改写问题可能对问题提供有效的预先处理 (provide reasonable preconditioning)。如果最优函数接近identity mappings,那么优化将会变得容易些。 实验证明该思路是对的。
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
Network Architectures
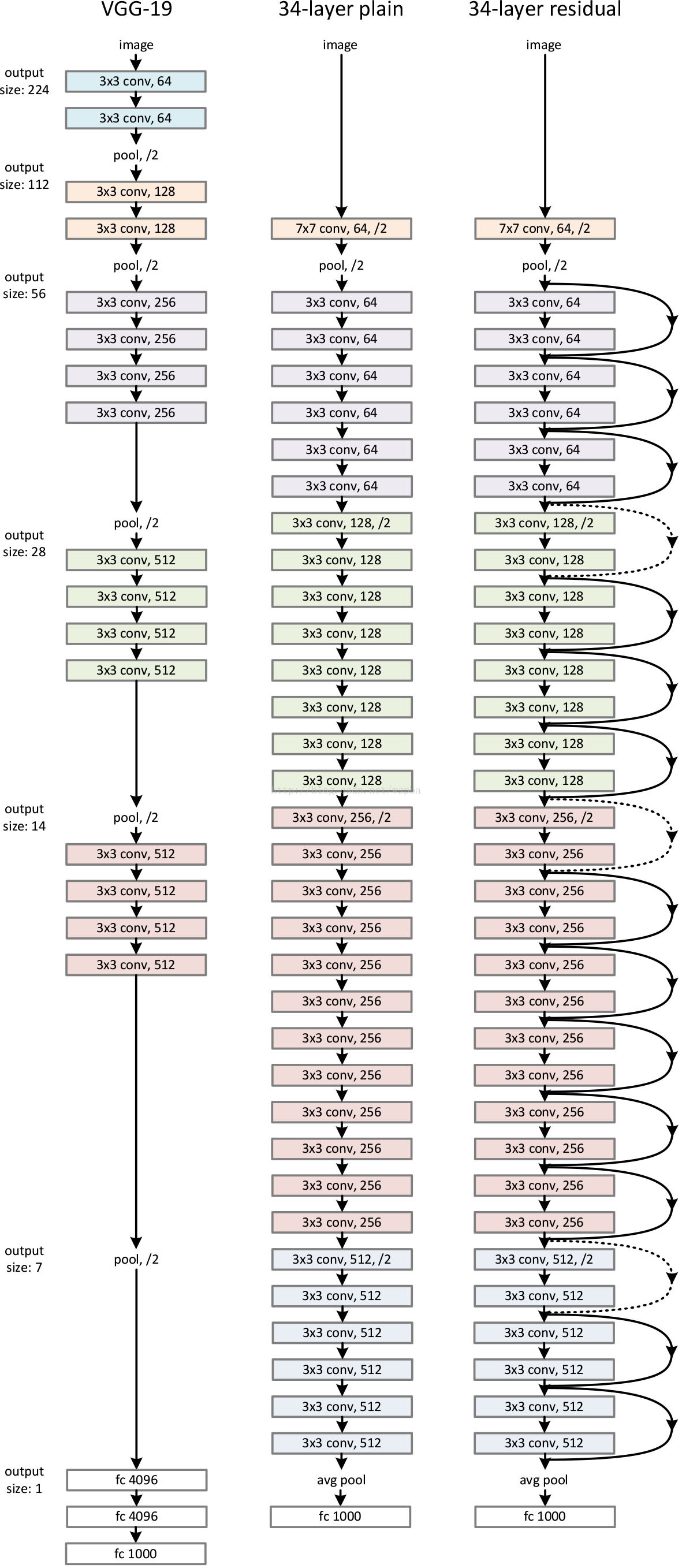
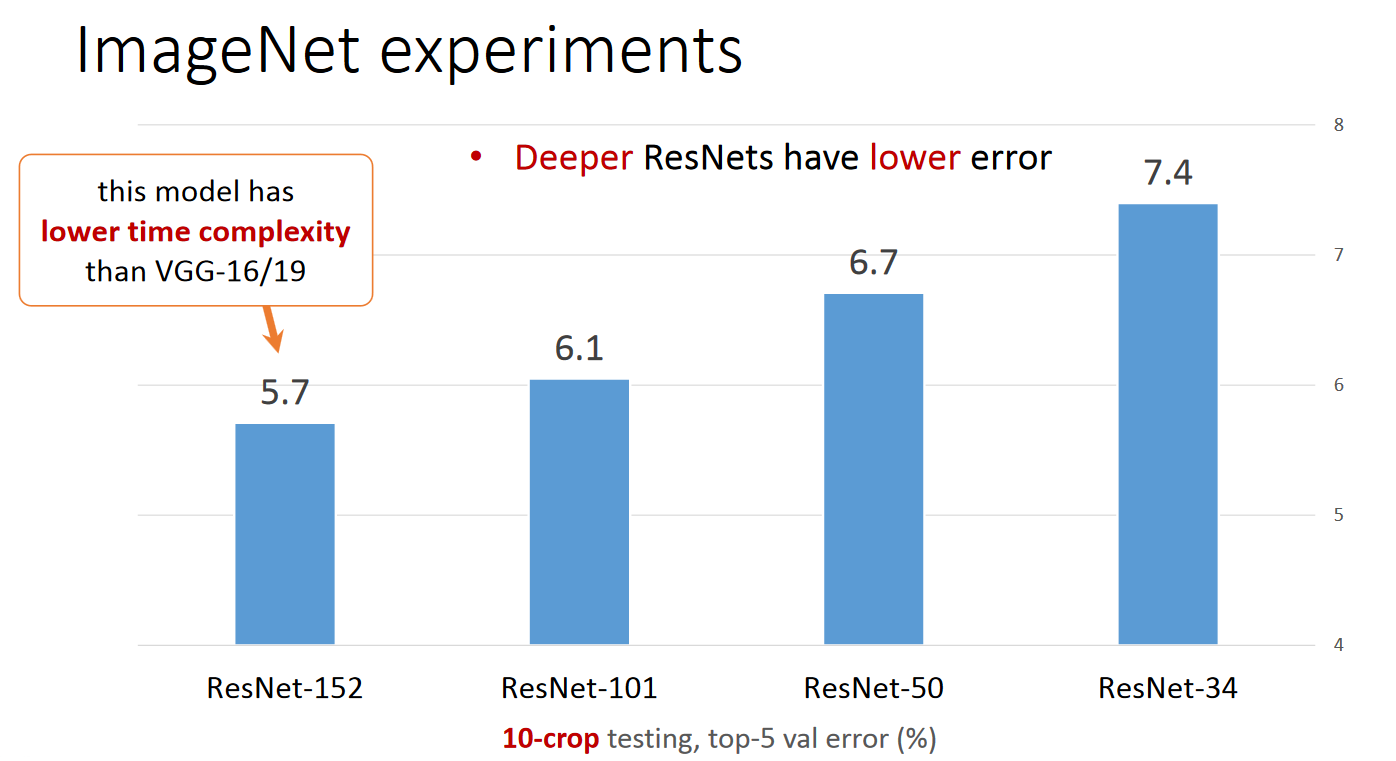
首先构建了一个18层和一个34层的plain网络,即将所有层进行简单的铺叠,然后构建了一个18层和一个34层的residual网络,仅仅是在plain上插入了shortcut,而且这两个网络的参数量、计算量相同,并且和之前有很好效果的VGG-19相比,计算量要小很多。(36亿FLOPs VS 196亿FLOPs,FLOPs即每秒浮点运算次数。)这也是作者反复强调的地方,也是这个模型最大的优势所在。
Plain Network 主要是受 VGG 网络启发,主要采用3*3滤波器,遵循两个设计原则:1)对于相同输出特征图尺寸,卷积层有相同个数的滤波器,2)如果特征图尺寸缩小一半,滤波器个数加倍以保持每个层的计算复杂度。通过步长为2的卷积来进行降采样。一共34个权重层。需要指出,这个网络与VGG相比,滤波器要少,复杂度要小。
对ResNet的解读
基本的残差网络其实可以从另一个角度来理解,如下图所示:
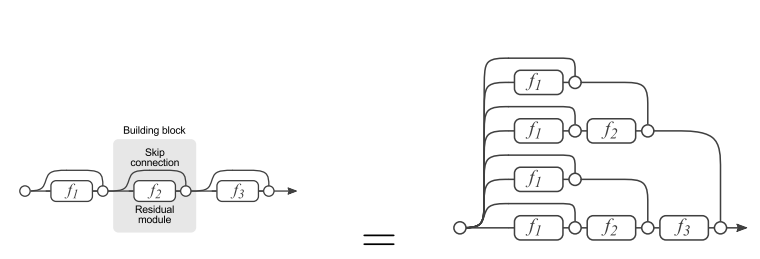
残差网络单元其中可以分解成右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。下面来说明为什么可以这样理解
删除网络的一部分
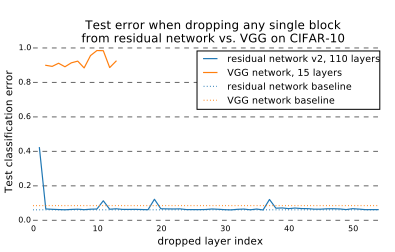
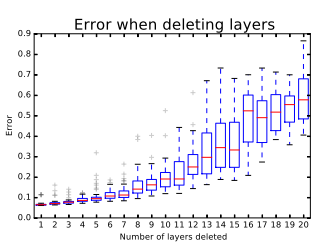
如果把残差网络理解成一个Ensambling系统,那么网络的一部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该适合删除的残差单元的个数成正比的,论文里的结论也印证了这个猜测。
下图是比较VGG和ResNet分别删除一层网络的分类错误率变化
下图是ResNet分类错误率和删除的基本残差网络单元个数的关系
ResNet的真面目
ResNet的确可以做到很深,但是从上面的介绍可以看出,网络很深的路径其实很少,大部分的网络路径其实都集中在中间的路径长度上,如下图所示:
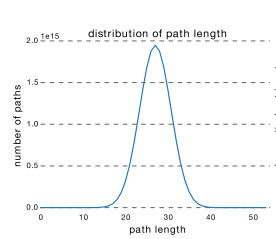
从这可以看出其实ResNet是由大多数中度网络和一小部分浅度网络和深度网络组成的,说明虽然表面上ResNet网络很深,但是其实起实际作用的网络层数并没有很深,我们能来进一步阐述这个问题,我们知道网络越深,梯度就越小,如下图所示 :
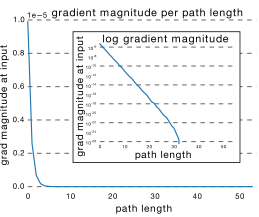
而通过各个路径长度上包含的网络数乘以每个路径的梯度值,我们可以得到ResNet真正起作用的网络是什么样的,如下图所示 :
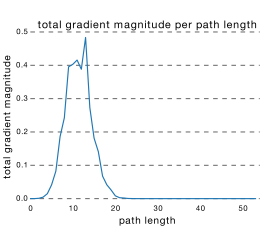
我们可以看出大多数的梯度其实都集中在中间的路径上,论文里称为effective path。
从这可以看出其实ResNet只是表面上看起来很深,事实上网络却很浅。
所示ResNet真的解决了深度网络的梯度消失的问题了吗?似乎没有,ResNet其实就是一个多人投票系统。
Experiments
1. Cifar10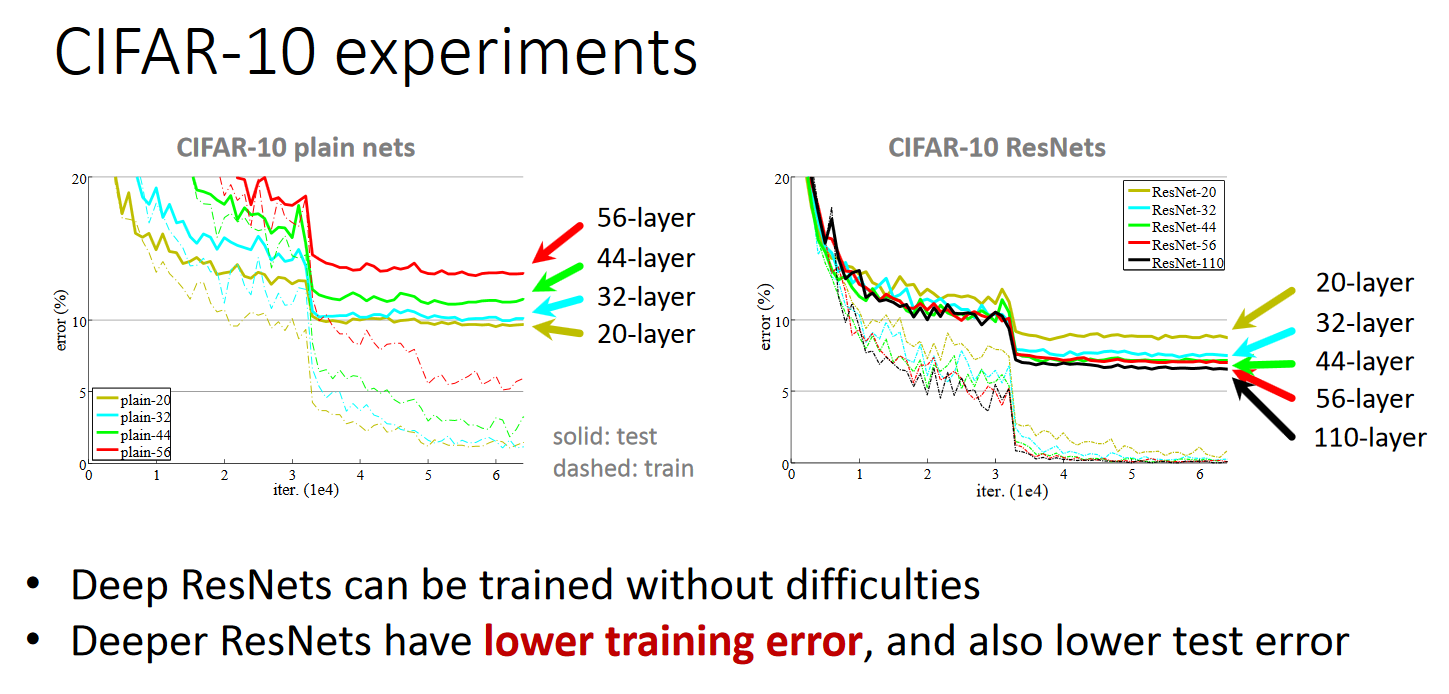
2. ImageNet
针对 ImageNet网络的实现,图像以较小的边缩放至[256,480],这样便于 scale augmentation,然后从中随机裁出 224*224。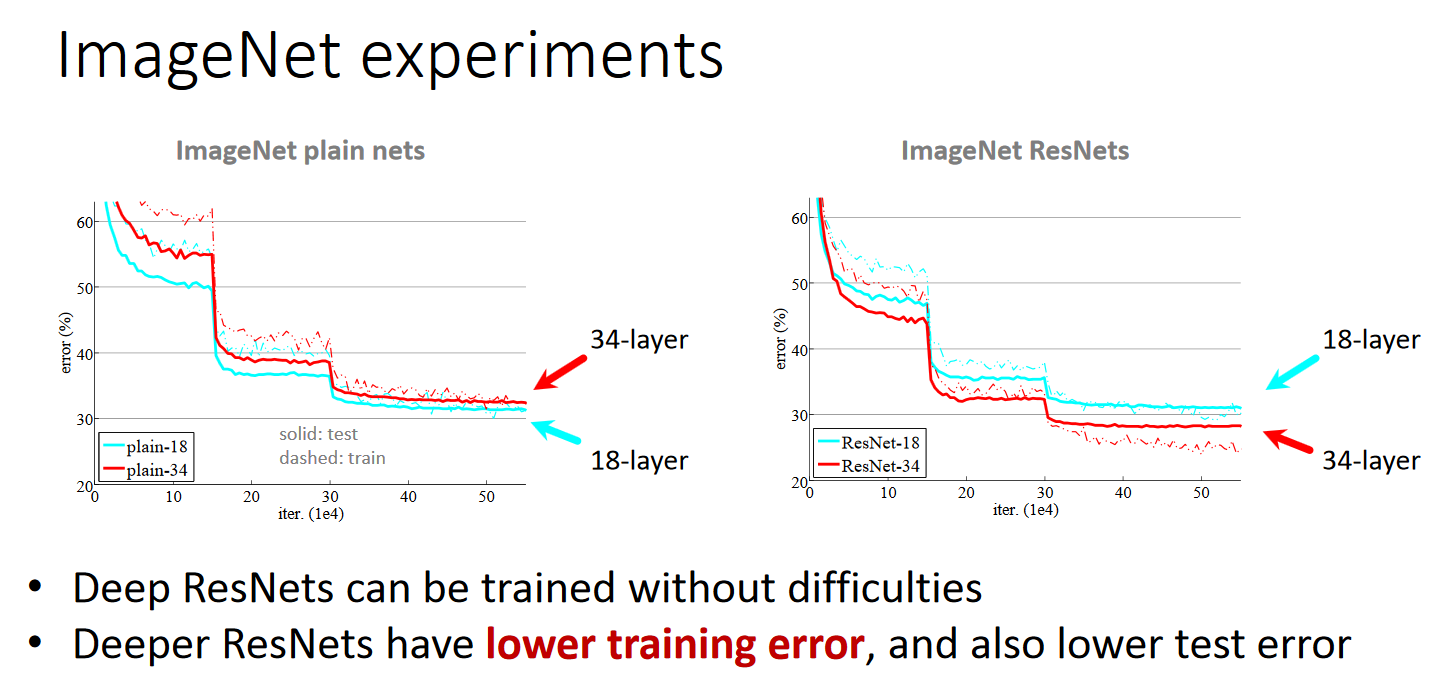
在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
对于shortcut的方式,作者提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
进一步实验,作者又提出了deeper的residual block:
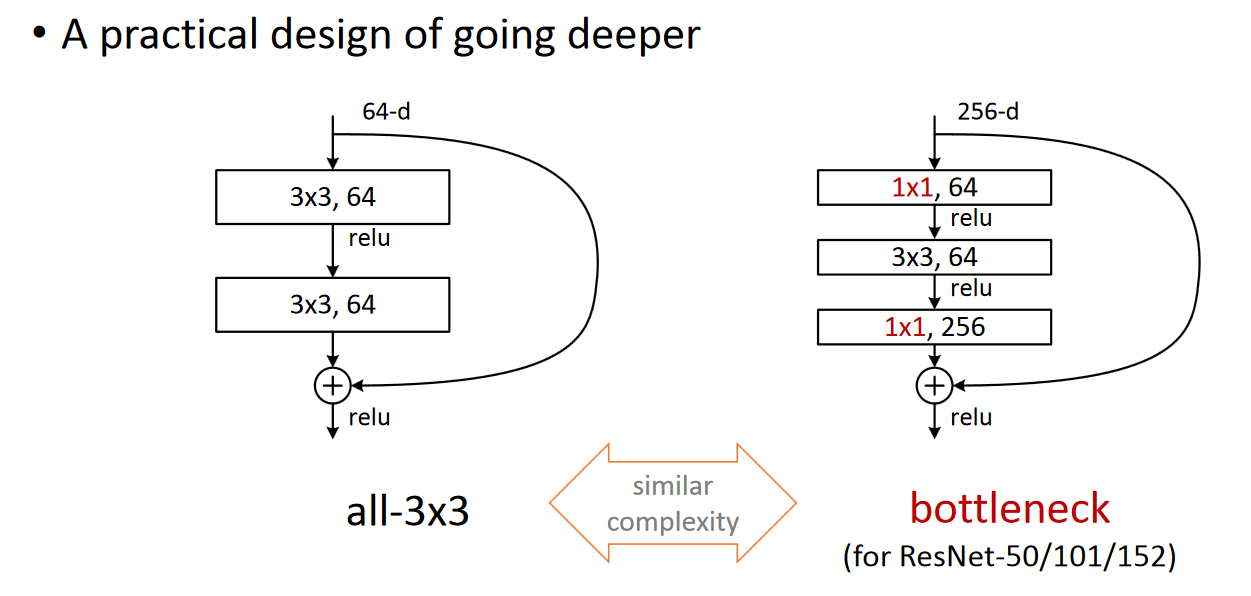
计算时间和层数
代码实现
#coding:utf-8
#导入对应的库
import collections
import tensorflow as tf
import time
import math
from datetime import datetime
slim = tf.contrib.slim
#定义了一个block类
class Block(collections.namedtuple('Bolck', ['scope', 'init_fn', 'args'])):
'A named tuple describing a ResNet block.'
#定义了一个下采样函数
def subsample(inputs, factor, scope = None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride = factor, scope = scope)
#定义conv2d_same函数创建卷积层
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope = None):
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride = 1, padding = 'SAME', scope = scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride = stride, padding = 'VALID', scope = scope)
#定义堆叠blocks的函数
#@这个符号用于装饰器中,用于修饰一个函数,把被修饰的函数作为参数传递给装饰器
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections = None):
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
with tf.variable_scope('unit_%d' %(i + 1), values = [net]):
unit_depth, unit_depth_bottleneck, unit_stride = unit
net = block.unit_fn(net, depth = unit_depth,
unit_depth_bottleneck = unit_depth_bottleneck,
stride = unit_stride)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
return net
#创建ResNet通用的arg_scope
def resnet_arg_scope(is_training = True,
weight_decay = 0.0001,
batch_norm_decay = 0.997,
batch_norm_epsilon = 1e-5,
batch_norm_scale = True):
batch_norm_params = {
'is_training': is_training,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer = slim.l2_regularizer(weight_decay),
weights_initializer = slim.variance_scaling_initializer(),
activation_fn = tf.nn.relu,
normalizer_fn = slim.batch_norm,
normalizer_params = batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.max_pool2d], padding = 'SAME') as arg_sc:
return arg_sc
#定义bottleneck残差学习单元
@slim.add_arg_scope
def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections = None, scope = None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank = 4)
preact = slim.batch_norm(inputs, activation_fn = tf.nn.relu, scope = 'preact')
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride = stride, normalizer_fn = None, activation_fn = None, scope = 'shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride = 1, scope = 'conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope = 'conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride = 1, normalizer_fn = None, activation_fn = None, scope = 'conv3')
output = shortcut + residual
return slim.utils.collect_named_outputs(outputs_collections, sc.name, output)
#定义生成ResNet V2主函数
def resnet_v2(inputs, blocks, num_classes = None, global_pool = True, include_root_block = True, reuse = None, scope = None):
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse = reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections = end_points_collection):
net = inputs
if include_root_block:
with slim.arg_scope([slim.conv2d], activation_fn = None, normalizer_fn = None):
net = conv2d_same(net, 64, 7, stride = 2, scope = 'conv1')
net = slim.max_pool2d(net, [3, 3], stride = 2, scope = 'pool1')
net = slim.batch_norm(net, activation_fn = tf.nn.relu, scope = 'postnorm')
if global_pool:
net = tf.reduce_mean(net, [1, 2], name = 'pool5', keep_dims = True)
if num_classes is not None:
net = slim.conv2d(net, num_classes, [1, 1], activation_fn = None, normalizer_fn = None, scope = 'logits')
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if num_classes is not None:
end_points['predictions'] = slim.softmax(net, scope = 'predictions')
return net, end_points
#定义50层的ResNet
def resnet_v2_50(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_50'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 1024, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
#定义101层的ResNet
def resnet_v2_101(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_101'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
#定义152层的ResNet
def resnet_v2_152(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_152'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
#定义200层的ResNet
def resnet_v2_200(inputs, num_classes = None, global_pool = True, reuse = None, scope = 'resnet_v2_200'):
blocks = [
Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]),
Block('block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]),
Block('block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]),
Block('block4', bottleneck, [(2048, 512, 1)] * 3)]
return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block = True, reuse = reuse, scope = scope)
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(), info_string, num_batches, mn, sd))
batch_size = 32
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(resnet_arg_scope(is_training = False)):
net, end_points = resnet_v2_152(inputs, 1000)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches = 100
time_tensorflow_run(sess, net, "Forward")